Hi rekan-rekan Makers,
Bertemu lagi di seri ML.NET, saat kita ingin memilih features sebagai input untuk algoritma ML kita perlu tahu seberapa besar kontribusi suatu feature (kolom input) terhadap hasil prediksi. Hal ini dapat dilakukan dengan fitur PFI (Permutation Feature Importance).
Dalam use case sehari-hari sebagai contoh seorang montir saat menganalisa kerusakan mesin mobil perlu memahami beberapa faktor utama yang menjadi indikator kerusakan. Jika mesin bermasalah biasanya yang diobservasi adalah bunyi mesin, getaran, putaran, kondisi fisik, penggunaan BBM, sedangkan faktor seperti kondisi body, interior, suhu AC, tidak punya pengaruh signifikan dalam menentukan kondisi mesin. Semakin baik kita bisa menjelaskan model ML kita, semakin yakin kita dalam menggunakannya dalam mengambil keputusan.
Salah satu cara dalam menentukan features yang berkontribusi pada model Regresi dan Klasifikasi adalah PFI, Permutation Feature Importance. teknik ini mengadopsi Breiman’s Random Forestspaper (lihat bagian 10). Cara kerjanya adalah mengacak nilai dari satu feature untuk seluruh dataset, lalu mengukur penurunan yang terjadi pada metrik pengukuran akurasi model. Semakin besar perubahan, semakin tinggi pengaruh feature tersebut. Sehingga kita bisa memilah feature-feature yang penting pada model, mempercepat proses training dan mengurangi noise.
Untuk rekan-rekan yang belum mengikuti seri ini dari awal silakan baca dari artikel ini. Adapun beberapa hal yang sebelumnya dibahas antara lain regression, binary classification, multiclass classification, clustering, time-series, recommendation dengan matrix factorization, recommendation dengan field aware factorization, dan Transfer Learning.
Nah kita akan menggunakan dataset tentang pengukuran performa CPU dari berbagai vendor dari UCI. Data ini memiliki attribut antara lain:
- vendor name : nama vendor-vendor cpu
- Model Name: jenisnya
- MYCT: machine cycle time dalam nanosecond (integer)
- MMIN: minimum main memory dalam kilobytes (integer)
- MMAX: maximum main memory dalam kilobytes (integer)
- CACH: cache memory dalam kilobytes (integer)
- CHMIN: minimum channels dalam units (integer)
- CHMAX: maximum channels dalam units (integer)
- PRP: published relative performance (integer)
- ERP: estimated relative performance from the original article (integer), attribut ini menjadi label, attribut lainnya menjadi features
selanjutnya, rekan-rekan memastikan sudah menginstall .NET Core / .NET Framework versi terakhir, dalam artikel ini saya menggunakan .NET Core versi 2.2. Jika belum silakan download disini. Jika belum memiliki IDE silakan download visual studio and vs code.
Langkah pertama silakan buat project baru dengan tipe console application. Kalau dengan dengan .Net Core bisa menggunakan CLI, silakan buka terminal atau command line (cmd.exe). Lalu ketik:
mkdir FeatureSelectionWithPFI
Lalu masuk ke folder yang baru dibuat dengan mengetik:
cd FeatureSelectionWithPFI
Selanjutnya buat aplikasi console dengan mengetik:
dotnet new console
Kita perlu menambahkan nuget package ML.NET dan algoritma Recommendation dengan mengetik:
dotnet add package Microsoft.ML
Kemudian buatlah folder dengan nama “Data” dengan mengetik:
mkdir Data
Lalu download semua file dari link ini, dan masukan ke folder “Data” tersebut.
Kemudian buka dengan visual studio code folder “FeatureSelectionWithPFI”
pada Program.cs masukan namespace ML.NET dengan mengetik pada bagian atas:
using Microsoft.ML;
using Microsoft.ML.Data;
using System;
using System.Collections.Immutable;
using System.IO;
using System.Linq;
Buatlah class baru dengan nama “CpuData.cs” masukan kode berikut:
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Text;
namespace FeatureSelectionWithPFI
{
class CpuData
{
[LoadColumn(0)]public string Vendor { get; set; }
[LoadColumn(1)]public string Model { get; set; }
[LoadColumn(2)]public float MYCT { get; set; }
[LoadColumn(3)]public float MMIN { get; set; }
[LoadColumn(4)]public float MMAX { get; set; }
[LoadColumn(5)]public float CACH { get; set; }
[LoadColumn(6)]public float CHMIN { get; set; }
[LoadColumn(7)]public float CHMAX { get; set; }
[LoadColumn(8)]public float PRP { get; set; }
[LoadColumn(9)][ColumnName("Label")]public float ERP { get; set; }
}
}
Ini adalah representasi dari dataset yang digunakan, lalu kembali ke “Program.cs” masukan kode berikut pada void main:
//Create MLContext
MLContext mlContext = new MLContext(seed:0);
var filePath = GetAbsolutePath("../../../Data/machine.data");
//Load Data File
IDataView data = mlContext.Data.LoadFromTextFile<CpuData>(filePath,',',false);
//var xx = data.Preview();
// 1. Get the column name of input features.
var featureColumnNames =
data.Schema
.Select(column => column.Name)
.Where(columnName => columnName != "Label" && columnName != "Vendor" && columnName != "Model").ToList();
featureColumnNames.AddRange(new string []{"ModelEncoded","VendorEncoded" });
// 2. Define estimator with data pre-processing steps
IEstimator<ITransformer> dataPrepEstimator = mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "VendorEncoded",inputColumnName:"Vendor")
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "ModelEncoded", inputColumnName: "Model"))
.Append(mlContext.Transforms.Concatenate("Features", featureColumnNames.ToArray()))
.Append(mlContext.Transforms.NormalizeMinMax("Features"));
// 3. Create transformer using the data pre-processing estimator
ITransformer dataPrepTransformer = dataPrepEstimator.Fit(data);
// 4. Pre-process the training data
IDataView preprocessedTrainData = dataPrepTransformer.Transform(data);
// 5. Define Stochastic Dual Coordinate Ascent machine learning estimator
var sdcaEstimator = mlContext.Regression.Trainers.Sdca();
// 6. Train machine learning model
var sdcaModel = sdcaEstimator.Fit(preprocessedTrainData);
Kode diatas seperti saat kita memprediksi nilai dengan algoritma regresi. Lalu lanjutkan dengan memasukan kode berikut:
ImmutableArray<RegressionMetricsStatistics> permutationFeatureImportance = mlContext.Regression
.PermutationFeatureImportance(sdcaModel, preprocessedTrainData, permutationCount: 3);
// Order features by importance
var featureImportanceMetrics =
permutationFeatureImportance
.Select((metric, index) => new { index, metric.RSquared })
.OrderByDescending(myFeatures => Math.Abs(myFeatures.RSquared.Mean));
Console.WriteLine("Feature\tPFI");
foreach (var feature in featureImportanceMetrics)
{
if (feature.index < 7)
Console.WriteLine($"{featureColumnNames[feature.index],-20}|\t{feature.RSquared.Mean:F6}");
}
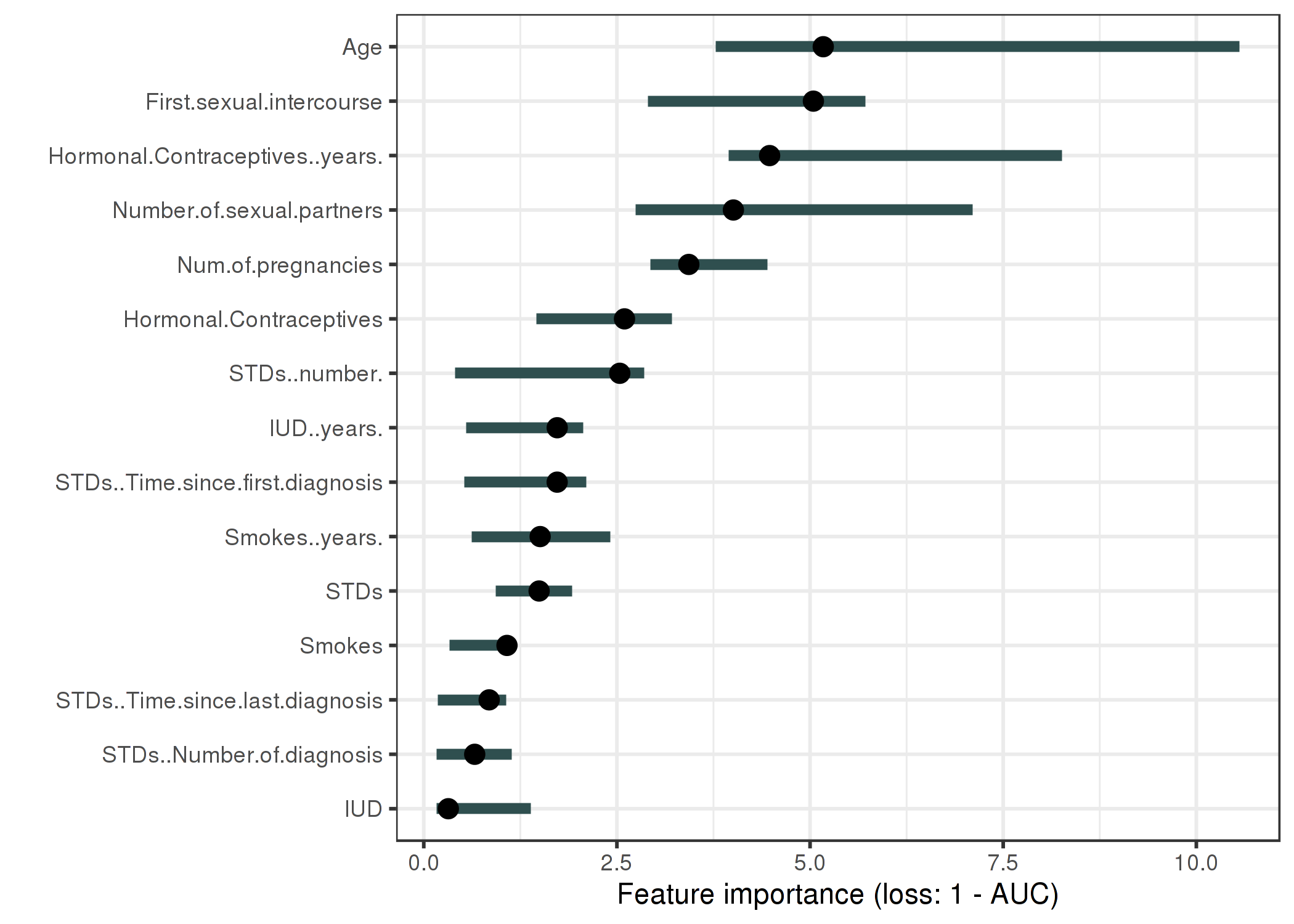
Kode diatas akan menguji setiap kolom feature dengan nilai random, lalu mengukur nilai rata-rata dari RSquare. Untuk mengetahui mana kolom paling berpengaruh silakan diurutkan dari yang terbesar (absolut). Bisa disimpulkan 5 kolom paling penting antara lain:
- MMAX
- PRP
- MMIN
- CACH
- CHMAX

Nah sekarang rekan-rekan punya perangkat yang membantu dalam menentukan features pada model ML. Source code lengkap bisa diperoleh dari sini.
Semoga bermanfaat untuk rekan-rekan dalam berkreasi dengan ML.NET.
Salam Makers ;D
![]()