Hi Rekan Devs,
Pie kabare ? semoga sehat” selalu. Sudah beberapa minggu ga ketemu, sekarang nyempetin lagi nulis biar ga kaku jari-jari. Nah temen-temen tau khan kalau kita bikin solusi RAG (Retrieval Augmented Generation) kita perlu simpen data-data teks di vektor database, agar memudahkan pencarian nanti. Btw apa itu RAG ? singkatnya temen-temen biasa kalau chat dengan dokumen teks dengan LLM perlu mengubah data yang akan dijadikan konteks saat prompting menjadi bentuk vektor (array of float number). Nah kalau datanya banyak, biasa di potong kecil-kecil biar muat dengan jendela konteks sesuai dengan kapasitas model yang digunakan, biasa satuannya dalam token. Setiap model LLM punya kapasitas jendela konteks yang berbeda, sebagai contoh model gpt-3.5-turbo-16k bisa menerima request konteks sebesar 16.000 token, kira-kira seperti 20 halaman teks dalam sekali panggil (request).
Mungkin pernah dengan Qdrant, Weaviate, Azure Cognitive Search, Chroma, dan banyak lagi, itu semua contoh produk yang bisa digunakan sebagai vektor database. Nah kalau digeneralisir, mereka semua menyimpan vektor ke dalam collection, lalu setiap potongan teks akan diberikan key, dan tambahan beberapa property lain yang mendukung seperti timestamp, dsb. Mestinya kalau simpel gitu bisa donk bikin sendiri ? Haha namanya juga orang kurang kerjaan, gimana kalau kita coba bikin sendiri.
Nah tujuan project ini sebenernya untuk bahan belajar aja, cara kerja vektor db sederhana. Speknya kaya gini:
Konsep:
- Bisa nyimpen data potongan teks dalam bentuk vektor
- Kita bisa membedakan kategori data menggunakan collection
- Setiap collection memiliki koleksi data vektor (vektor record) yang di berikan key unik, dan beberapa property metadata pendukung, dan juga timestamp
- Sehingga analoginya collection seperti tabel, record vektor seperti baris data di tabel tersebut
- Ada fitur untuk memanipulasi data collection dan record tersebut, mirip kaya CRUD dah..
Implementasi:
- Kalau temen baca update dari .NET 8, Announcing .NET 8 RC2 – .NET Blog (microsoft.com) Tim .NET itu semakin gencar nambahin fitur AI ke dalam librarynya, seperti contoh System.Numerics.Tensors.TensorPrimitives yang berisi beberapa fungsi tensor, salah satu yang kita butuh itu CosineSimilarity, algoritma untuk melihat kemiripan antara dua vektor. Ini bisa kita pake di database vektor kita.
- Selama aplikasi berjalan data bisa kita simpan di memory, tapi supaya persistent kita bisa simpan ke file. Supaya cepat kita bisa pake MessagePack, ini library serializer super cepat.
- Nah untuk mengujinya kita bikinkan juga konektor untuk salah satu library orkestrasi yang keren dari Microsoft yaitu Semantic Kernel. Sehingga kita bisa memanfaatkan vektor db kita dengan library ini.
- Tinggal koding dah, saya ga usah jelasin bagian ini karena temen-temen disini tentunya lebih ahli. Silakan saja buka projectnya dari repo berikut: Gravicode/MerkonVectorDB: This is an experimental project to create Vector DB with .NET (github.com)
Nah silakan clone reponya, jalankan aplikasi contohnya, tadaaa… beres deh vektor db versi kita sendiri.

Sedikit keterangan mengenai cara kerja sample programnya:
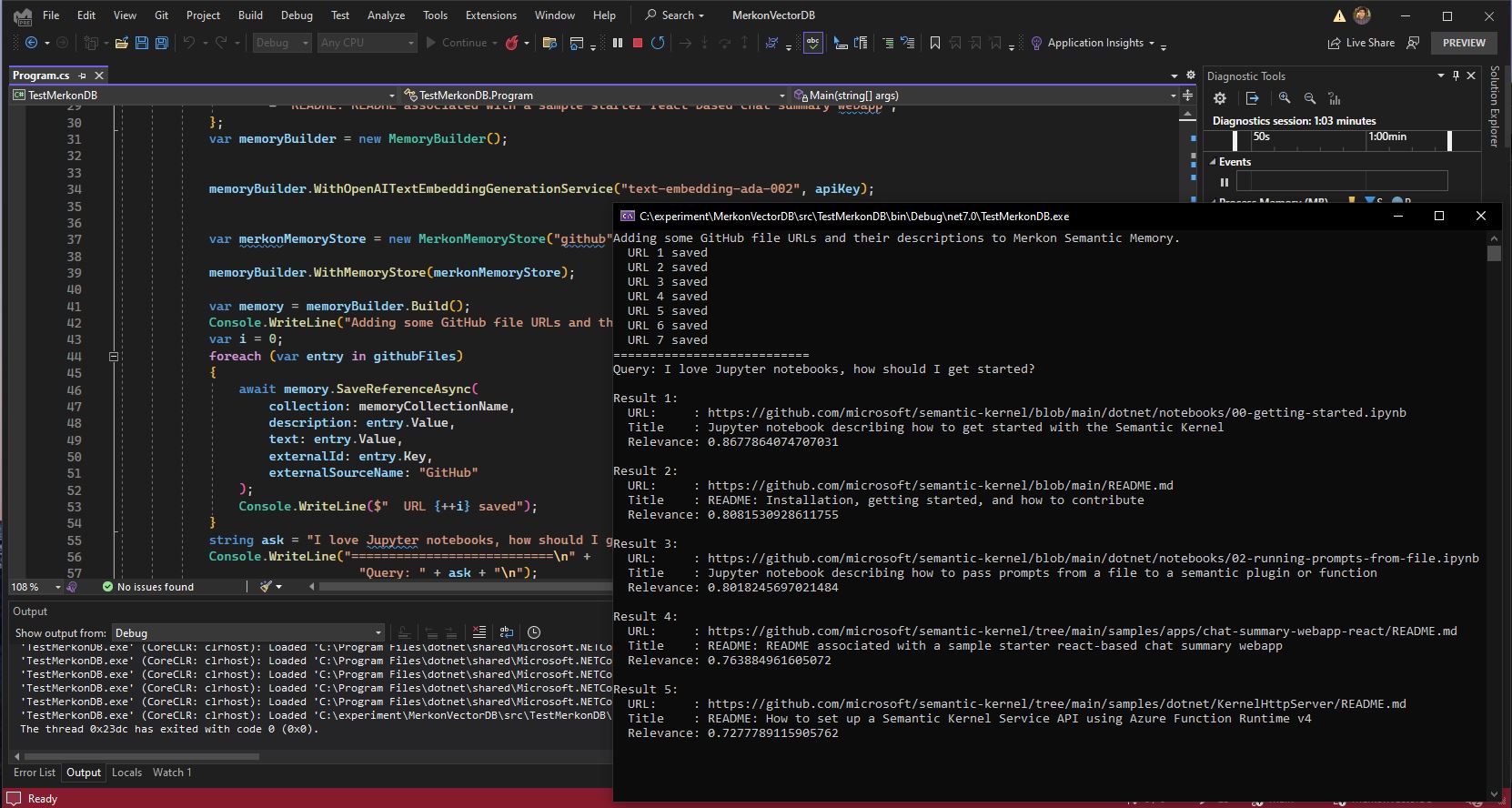
- Kita masukan beberapa sampel potongan teks data yaitu link-link github dan judulnya ke vektor database. Teks di ubah jadi vektor itu dibantu oleh Model Open AI yang namanya text-embedding-ada-002
- Lalu kita coba query ke vektor db untuk melihat teks-teks yang paling mirip dengan prompt yang kita tulis, nah kalau kita lihat semantic kernel ini akan memanggil metode-metode yang ada di database vektor kita melalui connector custom yang kita buat
Note: Jangan lupa Open AI keynya kalian isi dengan key kalian sendiri. Silakan ubek-ubek sendiri kode-nya nanti paham sendiri.
Semoga bermanfaat, terus berkarya.
Salam Dev
![]()