Hi Rekan Devs,
Pa kabar ? sebentar lagi puasa, pada jaga kesehatan yo..
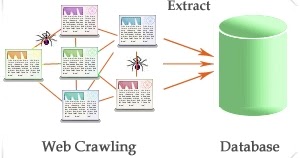
Nah, kali ini kita akan coba membuat aplikasi sederhana untuk melakukan crawling, atau bahasa asiknya ngubek-ngubek isi website untuk mendapatkan konten tertentu. Cocok ni untuk rekan-rekan yang lagi riset atau bikin skripsi tentang web crawler, text mining, sentiment analysis, media monitoring, dsb. Ini bisa menjadi sebagai salah satu sumber datanya untuk datasetnya yaitu web.
Sebagai contoh, kali ini kita akan coba bikin crawler sederhana yang akan membaca isi halaman-halaman yang ada di portal berita tertentu dan kita filter hanya beberapa topik yang kita inginkan berdasarkan url address-nya.
Ok, memang ada beberapa library untuk melakukan crawling web cuma kali ini kita akan coba yang namanya Abot. Kalau dari yang bikin mereka mendefinisikan sebagai “open source C# web crawler built for speed and flexibility”, cek web mereka di sjdirect/abot: Cross Platform C# web crawler framework built for speed and flexibility. Please star this project! +1. (github.com)
langkah selanjutnya adalah mempersiapkan dev environment rekan-rekan, seperti biasa install ini dulu yah..
- Download .NET (Linux, macOS, and Windows) (microsoft.com)
- Download Visual Studio Tools – Install Free for Windows, Mac, Linux (microsoft.com)
- Lalu bikin aplikasi console sederhana, buka command line / terminal lalu:
- bikin folder baru : mkdir NewsCrawler
- masuk ke folder tersebut : cd NewsCrawler
- bikin project console baru : dotnet new console
- Lalu tambah beberapa library: dotnet add package Abot
- Lalu tambah beberapa library: dotnet add package HtmlAgilityPack
- Lalu tambah beberapa library: dotnet add package Newtonsoft.Json
- Lalu edit file Program.cs dengan VSCode atau Visual Studio, atau notepad, masukan kode berikut:
using Abot2.Crawler;
using Abot2.Poco;
using HtmlAgilityPack;
using Newtonsoft.Json;
var crawl = new WebCrawler();
var url = "https://kompas.com/";
crawl.Start(url);
Console.ReadLine();
public class WebCrawler
{
List<Crawled>? CrawledItems { set; get; }
string[] topics = new string[] { "jokowi", "ikn", "ibukota" };
public void Start(string UrlWeb)
{
Console.WriteLine("start crawler..");
CrawledItems = new List<Crawled>();
DoCrawl(UrlWeb);
Console.ReadLine();
}
async void DoCrawl(string UrlWeb)
{
CrawlConfiguration crawlConfig = new CrawlConfiguration();
crawlConfig.CrawlTimeoutSeconds = 100;
crawlConfig.MaxConcurrentThreads = 10;
crawlConfig.MaxPagesToCrawl = 5000;
crawlConfig.UserAgentString = "abot v1.0 http://code.google.com/p/abot";
//Will use app.config for confguration
PoliteWebCrawler crawler = new PoliteWebCrawler();
crawler.PageCrawlStarting += Crawler_PageCrawlStarting;
crawler.PageCrawlCompleted += Crawler_PageCrawlCompleted;
crawler.PageCrawlDisallowed += Crawler_PageCrawlDisallowed;
crawler.PageLinksCrawlDisallowed += Crawler_PageLinksCrawlDisallowed;
CrawlResult result = await crawler.CrawlAsync(new Uri(UrlWeb));
Console.WriteLine("jumlah crawled content :" + result.CrawlContext.CrawledCount);
if (result.ErrorOccurred)
Console.WriteLine("Crawl of {0} completed with error: {1}", result.RootUri.AbsoluteUri, result.ErrorException.Message);
else
Console.WriteLine("Crawl of {0} completed without error.", result.RootUri.AbsoluteUri);
//save result
SaveToDB();
}
void Crawler_PageLinksCrawlDisallowed(object? sender, PageLinksCrawlDisallowedArgs e)
{
CrawledPage crawledPage = e.CrawledPage;
Console.WriteLine("Did not crawl the links on page {0} due to {1}", crawledPage.Uri.AbsoluteUri, e.DisallowedReason);
}
void Crawler_PageCrawlDisallowed(object? sender, PageCrawlDisallowedArgs e)
{
PageToCrawl pageToCrawl = e.PageToCrawl;
Console.WriteLine("Did not crawl page {0} due to {1}", pageToCrawl.Uri.AbsoluteUri, e.DisallowedReason);
}
void Crawler_PageCrawlCompleted(object? sender, PageCrawlCompletedArgs e)
{
CrawledPage crawledPage = e.CrawledPage;
if (isContains(crawledPage.Uri.AbsoluteUri))
{
var item = new Crawled() { Url = crawledPage.Uri.AbsoluteUri, Description = crawledPage.Content.Text };
CrawledItems.Add(item);
Console.WriteLine($"{item.Url} => ");
}
if (crawledPage.HttpRequestException != null || crawledPage.HttpResponseMessage.StatusCode != System.Net.HttpStatusCode.OK)
Console.WriteLine("Crawl of page failed {0}", crawledPage.Uri.AbsoluteUri);
Console.WriteLine("Crawl of page succeeded {0}", crawledPage.Uri.AbsoluteUri);
if (string.IsNullOrEmpty(crawledPage.Content.Text))
Console.WriteLine("Page had no content {0}", crawledPage.Uri.AbsoluteUri);
}
void Crawler_PageCrawlStarting(object? sender, PageCrawlStartingArgs e)
{
PageToCrawl pageToCrawl = e.PageToCrawl;
Console.WriteLine("About to crawl link {0} which was found on page {1}", pageToCrawl.Uri.AbsoluteUri, pageToCrawl.ParentUri.AbsoluteUri);
}
/// <summary>
/// Untuk filter url
/// </summary>
/// <param name="URL"></param>
/// <returns></returns>
bool isContains(string URL)
{
if (string.IsNullOrEmpty(URL)) return false;
foreach(var topic in topics)
{
if (URL.Contains(topic, StringComparison.InvariantCultureIgnoreCase)) return true;
}
return false;
}
/// <summary>
/// Untuk save ke file atau db
/// </summary>
/// <param name="SaveToFile"></param>
void SaveToDB(bool SaveToFile=false)
{
if (SaveToFile)
{
//save to file
var fileContent = JsonConvert.SerializeObject(CrawledItems);
File.WriteAllText("crawled-content.txt", fileContent);
}
else
{
var htmlDoc = new HtmlDocument();
foreach (var item in CrawledItems)
{
//get body
htmlDoc.LoadHtml(item.Description);
item.Description = htmlDoc.DocumentNode.SelectSingleNode("//body").InnerText;
//save to db, lengkapi sendiri
}
}
}
}
public class Crawled
{
public string Url { get; set; }
public string Description { get; set; }
}
Setelah itu silakan jalankan projectnya dengan menekan F5 (jika di visual studio) atau ketik “dotnet run” di terminal..
Penjelasan Singkat

Aplikasi ini akan melakukan crawling berdasarkan address website yang di set di variabel url, lalu setiap mendapatkan link baru, kita akan lakukan filtering url berdasarkan topik-topik yang ingin kita cari. Lalu setelah proses crawling selesai, ya kita tinggal masukan ke database atau file untuk kebutuhan data cleansing, atau preprocessing.
Nah tugas rekan-rekan coba kembangkan lagi untuk melakukan filtering berdasarkan content dari body page, gunakan regex atau semacamnya.. Lalu bisa lakukan sentiment analysis atau beberapa task seputar text mining..
Projectnya bisa rekan-rekan clone dari link berikut: Gravicode/NewsCrawler: Experimental project for crawling news portal to get some filtered topics (github.com)
Selamat berkarya,
Salam Dev ;D
![]()