Hi rekan-rekan Makers,
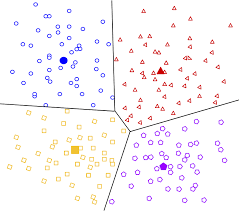
Bertemu lagi di seri ML.NET, kali ini kita akan mencoba menggunakan ML.NET untuk mengelompokan data berdasarkan karakteristik data tanpa dibantu dengan data label (unsupervised learning). Untuk rekan-rekan yang belum mengikuti seri ini dari awal silakan baca dari artikel ini. Adapun beberapa hal yang sebelumnya dibahas antara lain regression, binary classification atau multiclass classification.
Dataset yang akan kita gunakan adalah Data Sensus Dewasa di Amerika yang mengaitkan pendapatan dengan faktor sosial seperti Umur, Pendidikan, ras, dll. Kumpulan data pendapatan Us Adult diekstraksi oleh Barry Becker dari Basis Data Sensus AS 1994. Kumpulan data terdiri dari informasi anonim seperti pekerjaan, usia, negara asal, ras, capital gain, capital loss, pendidikan, kelas kerja dan banyak lagi. Setiap baris diberi label memiliki gaji lebih besar dari “> 50K” atau “<= 50K”. Lebih detailnya baca disini.
Beberapa attribut dari dataset ini adalah:
- age, attribut ini kita gunakan sebagai features
- workclass, attribut ini tidak kita gunakan
- fnlwgt, attribut ini kita gunakan sebagai features
- education, attribut ini tidak kita gunakan
- education_num, attribut ini kita gunakan sebagai features
- marital_status, attribut ini kita gunakan sebagai features
- occupation, attribut ini tidak kita gunakan
- relationship, attribut ini kita gunakan sebagai features
- race, attribut ini kita gunakan sebagai features
- sex, attribut ini kita gunakan sebagai features
- capital gain, attribut ini tidak kita gunakan
- capital loss, attribut ini tidak kita gunakan
- hours per week, attribut ini kita gunakan sebagai features
- native country, attribut ini tidak kita gunakan
- income, attribut ini tidak kita gunakan karena kita gunakan unsupervised learning
selanjutnya, rekan-rekan memastikan sudah menginstall .NET Core / .NET Framework versi terakhir, dalam artikel ini saya menggunakan .NET Core versi 2.2. Jika belum silakan download disini. Jika belum memiliki IDE silakan download visual studio and vs code.
Langkah pertama silakan buat project baru dengan tipe console application. Kalau dengan dengan .Net Core bisa menggunakan CLI, silakan buka terminal atau command line (cmd.exe). Lalu ketik:
mkdir IncomeClusteringApp
Lalu masuk ke folder yang baru dibuat dengan mengetik:
cd IncomeClusteringApp
Selanjutnya buat aplikasi console dengan mengetik:
dotnet new console
Kita perlu menambahkan nuget package ML.NET dengan mengetik:
dotnet add package Microsoft.ML
Kemudian buatlah folder dengan nama “Data” dengan mengetik:
mkdir Data
Lalu download file csv dari link ini, dan masukan ke folder “Data” tersebut.
Kemudian buka dengan visual studio code folder “IncomeClusteringApp”
pada Program.cs masukan namespace ML.NET dengan mengetik pada bagian atas:
using Microsoft.ML; using Microsoft.ML.Data; using System.Collections.Generic; using System.IO; using System.Linq;
Selanjutnya buatlah class dengan nama “IncomeData.cs” isikan kode berikut:
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Text;
namespace IncomeClusteringApp
{
public class IncomeData
{
[ColumnName("age"), LoadColumn(0)]public float age { get; set; }
[ColumnName("workclass"), LoadColumn(1)]public string workclass { get; set; }
[ColumnName("fnlwgt"), LoadColumn(2)]public float fnlwgt { get; set; }
[ColumnName("education"), LoadColumn(3)]public string education { get; set; }
[ColumnName("education_num"), LoadColumn(4)]public float education_num { get; set; }
[ColumnName("marital_status"), LoadColumn(5)]public string marital_status { get; set; }
[ColumnName("occupation"), LoadColumn(6)]public string occupation { get; set; }
[ColumnName("relationship"), LoadColumn(7)]public string relationship { get; set; }
[ColumnName("race"), LoadColumn(8)]public string race { get; set; }
[ColumnName("sex"), LoadColumn(9)]public string sex { get; set; }
[ColumnName("capital_gain"), LoadColumn(10)]public float capital_gain { get; set; }
[ColumnName("capital_loss"), LoadColumn(11)]public float capital_loss { get; set; }
[ColumnName("hours_per_week"), LoadColumn(12)]public float hours_per_week { get; set; }
[ColumnName("native_country"), LoadColumn(13)]public string native_country { get; set; }
[ColumnName("income"), LoadColumn(14)]public string income { get; set; }
}
}
Data class diatas merepresentasikan struktur data pada file csv. Selanjutnya kita masukan class prediction dengan nama “ClusterPrediction.cs”, berikut isinya:
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Text;
namespace IncomeClusteringApp
{
public class ClusterPrediction
{
[ColumnName("PredictedLabel")] public uint PredictedClusterId;
[ColumnName("Score")] public float[] Distances;
}
}
Class diatas berisi ID cluster yang terpilih, dan jarak antara sample data dengan centroid per-cluster. Selanjutnya buka file “Program.cs” lalu masukan pada void main kode berikut:
//Create MLContext
MLContext mlContext = new MLContext();
//Load Data File
IDataView trainData = mlContext.Data.LoadFromTextFile<IncomeData>(GetAbsolutePath("../../../Data/AdultIncome.csv"), separatorChar: ',', hasHeader: true);
//Data process configuration with pipeline data transformations
var dataPrepTransform = mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "workclass_encoded", inputColumnName: "workclass")
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "education_encoded", inputColumnName: "education"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "marital_status_encoded", inputColumnName: "marital_status"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "occupation_encoded", inputColumnName: "occupation"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "relationship_encoded", inputColumnName: "relationship"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "race_encoded", inputColumnName: "race"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "sex_encoded", inputColumnName: "sex"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding(outputColumnName: "native_country_encoded", inputColumnName: "native_country"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "age", "fnlwgt", "education_num", "marital_status_encoded", "relationship_encoded", "race_encoded", "sex_encoded", "hours_per_week" }))
.Append(mlContext.Transforms.NormalizeMinMax("Features", "Features"))
.AppendCacheCheckpoint(mlContext);
// Create data transformer
ITransformer dataPrepTransformer = dataPrepTransform.Fit(trainData);
IDataView transformedTrainingData = dataPrepTransformer.Transform(trainData);
Pada kode diatas, kita membuat mlcontext yaitu pipeline yang kita gunakan untuk memproses semua aktivitas ML. Selanjutnya kita muat data dari CSV, lalu kita lakukan beberapa transformasi data seperti melakukan kategorisasi terhadap beberapa kolom yang berisi teks, lalu tentukan kolom-kolom yang akan kita gunakan sebagai features. Kita gunakan semua kolom kecuali : workclass,education,occupation,capital gain, capital loss, native country. Tapi nanti rekan-rekan bisa mengeksplorasi sendiri dengan menggunakan kombinasi kolom-kolom lainnya. Selanjutnya kita pilih algoritma ML untuk kita gunakan untuk melakukan training:
// Choose learner
var CluteringEstimator = mlContext.Clustering.Trainers.KMeans(featureColumnName: "Features", numberOfClusters: 2);
// Build machine learning model
var trainedModel = dataPrepTransformer.Append(CluteringEstimator.Fit(transformedTrainingData));
Kita menggunakan algoritma k-means++, selanjutnya setelah dilakukan training, kita bisa mengevaluasi model ML kita dengan cara:
// Measure trained model performance
var testData = trainedModel.Transform(transformedTrainingData);
var testMetrics = mlContext.Clustering.Evaluate(testData);
Console.WriteLine($"*************************************************************************************************************");
Console.WriteLine($"* Metrics for Clustering model - Test Data ");
Console.WriteLine($"*------------------------------------------------------------------------------------------------------------");
Console.WriteLine($"* AverageDistance: {testMetrics.AverageDistance:0.###}");
Console.WriteLine($"* DaviesBouldinIndex: {testMetrics.DaviesBouldinIndex:0.###}");
Console.WriteLine($"* NormalizedMutualInformation:{testMetrics.NormalizedMutualInformation:#.###}");
Console.WriteLine($"*************************************************************************************************************");
Lalu kita simpan model kita ke dalam binary file dengan kode berikut:
var modelRelativePath = GetAbsolutePath("MLModel.zip");
mlContext.Model.Save(trainedModel, trainData.Schema, GetAbsolutePath(modelRelativePath));
Console.WriteLine("The model is saved to {0}", GetAbsolutePath(modelRelativePath));
Setelah itu kita coba muat ulang file model tersebut dan kita lakukan ujicoba dengan 2 sample data yang memiliki kategori income yang sama (<=50k).
ITransformer mlModel = mlContext.Model.Load(GetAbsolutePath(modelRelativePath), out DataViewSchema inputSchema);
var predEngine = mlContext.Model.CreatePredictionEngine<IncomeData, ClusterPrediction>(mlModel);
// Create sample data to do a single prediction with it
var sampleData1 = mlContext.Data.CreateEnumerable<IncomeData>(trainData, false).First();
var sampleData2 = mlContext.Data.CreateEnumerable<IncomeData>(trainData, false).Skip(1).First();
// Try a single prediction
ClusterPrediction predictionResult = predEngine.Predict(sampleData1);
Console.WriteLine($"Sample 1");
Console.WriteLine($"Cluster: {predictionResult.PredictedClusterId}");
Console.WriteLine($"Distances: {string.Join(" ", predictionResult.Distances)}");
Console.WriteLine($"Sample 2");
ClusterPrediction predictionResult2 = predEngine.Predict(sampleData2);
Console.WriteLine($"Cluster: {predictionResult2.PredictedClusterId}");
Console.WriteLine($"Distances: {string.Join(" ", predictionResult2.Distances)}");
Console.WriteLine("both sample must be on the same cluster..");
Oke pada PC yang saya gunakan kedua sample tersebut dalam cluster yang sama. Mungkin pemilihan kolom yang saya lakukan belum optimal, nah saatnya rekan-rekan bisa melakukan optimasi model agar akurasinya semakin baik. Source code lengkapnya dapat diunduh disini.

Semoga post ini bermanfaat, jangan lupa ikuti artikel seri ML.NET selanjutnya.
Salam Makers ;D
![]()