Hi Rekan Dev,
Sehat” ? Semoga iya. Nah kali ini kita akan coba mengisi akhir weekdays dengan mencoba membuat media monitoring sederhana yang fungsinya:
- Mengambil data dari twitter dengan keyword tertentu
- Melakukan teks preprocessing: bersihkan teks dari tanda baca, url, stopword, stemming
- Proses teks: menghitung jumlah kata yang muncul
- Gambar dalam bentuk word cloud
Nah, kita sama-sama tahu python jagonya kalau untuk teks mining, tapi jangan khawatir kita akan lakukan ini dengan C# haha.. Kenapa gitu ? karena pengen aja. Engga sih, intinya nanti makin asik kalau diintegrasikan dengan solusi web, mobile atau lainnya karena uda dalam 1 bahasa.
Nah beberapa resep yang kita perlukan antara lain:
Ambil Data dari Twitter
Nah ga usah pusing karena sudah banyak library twitter client yang tinggal pakai, disini kita coba pakai Getting Started — Tweetinvi 5.0.4 documentation (linvi.github.io) nah yang temen-temen perluin adalah bikin akun twitter dan bikin aplikasi baru agar dapat key” yang diperlukan untuk library ini: silakan buat di https://developer.twitter.com/en/apps/create
Kita hanya akan pakai fungsi search saja disini berdasarkan keyword yang akan di ketik user.
Teks Preprocessing: Bersihkan tanda baca, dan url atau bahkan numerik
Nah, temen-temen uda pada pinter lah ini, cukup pakai regex yah untuk ngebuang tanda baca, angka dan url link.
Teks Preprocessing: Remove Stopwords dan Stemming
Nah ini yang aga repot kalau nyari librarynya yang dukung bahasa Indonesia, syukurlah kita punya temen-temen dev python Indo yang bikinin library yang namanya Sastrawi, cek TKP : har07/PySastrawi: Indonesian stemmer. Python port of PHP Sastrawi project. (github.com)
Nah dengan library ini rekan-rekan itu bisa lakukan penghapusan stop word, kata umum yang biasanya muncul dalam jumlah besar dan dianggap tidak memiliki makna. Contoh stopword dalam bahasa Indonesia adalah “yang”, “dan”, “di”, “dari”, dll.
Lalu kita juga lakukan stemming, proses menghilangkan infleksi kata ke bentuk dasarnya, namun bentuk dasar tersebut tidak berarti sama dengan akar kata (root word). Misalnya kata “mendengarkan”, “dengarkan”, “didengarkan” akan ditransformasi menjadi kata “dengar”.
Lha ini khan python gimana pake librarynya di C#, ya bisa lah ada temen yang bae bikin library ini buat kita : pythonnet/pythonnet: Python for .NET is a package that gives Python programmers nearly seamless integration with the .NET Common Language Runtime (CLR) and provides a powerful application scripting tool for .NET developers. (github.com)
Teks Preprocessing: Word Counting
Nah, ini temen-temen sebenernya bisa aja bikin sendiri karena mudah ya, tapi biar asik kita pakai library NLTK, yaitu library python yang sangat mumpuni dalam melakukan teks mining. Nah kita ga akan pake semua fungsinya, kita cuma contohin aja salah satu case yang kita pakai disini yaitu ngitung kata yang muncul, dan lagi-lagi dibantu pythonnet untuk melakukan interoperabilitas ini.
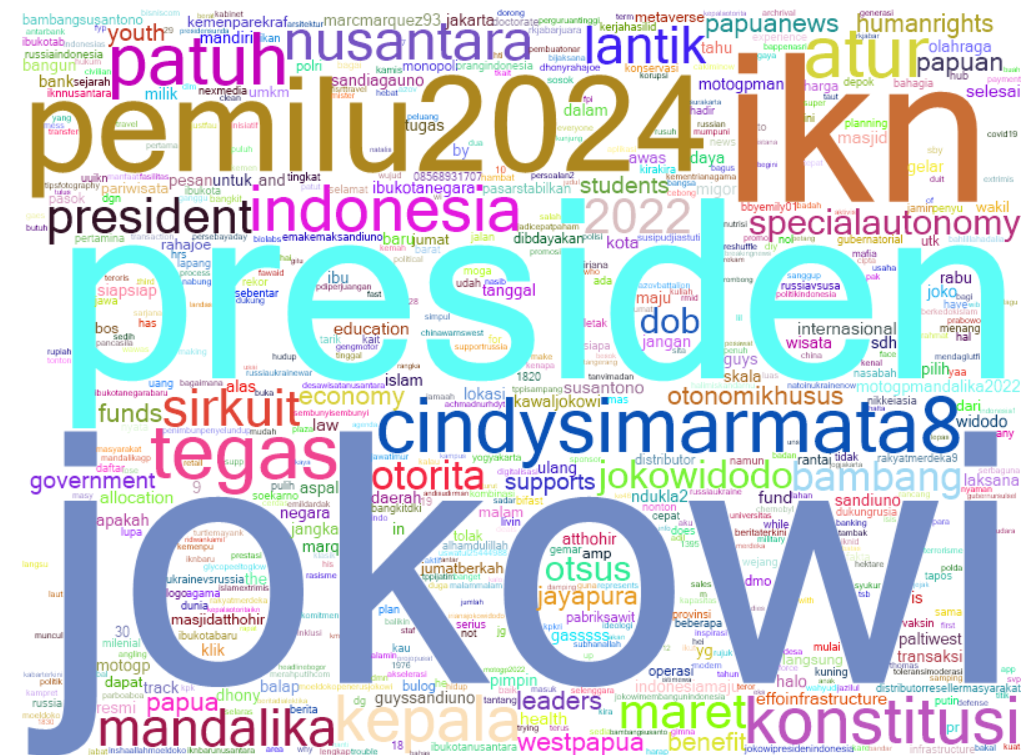
Visualisasi Data: Gambar Word Cloud
Visualisasi data penting banget untuk memudahkan kita dalam mengintepretasi data. Nah dengan word cloud kita akan menampilkan semua kata-kata yang ada dan besar ukuran kata tersebut mewakilkan banyaknya kemunculan kata tsb dari hasil pencarian di twitter. Kita pakai ini MustAl-Du/WordCloud: C# Sample to generate Word Cloud (github.com)
Jalankan Project
Temen-temen siapin lingkungan pengembangannya dulu masing-masing dengan cara:
- Download .NET (Linux, macOS, and Windows) (microsoft.com)
- Download Visual Studio Code – Mac, Linux, Windows
Setelah itu coba untuk projectnya dari Gravicode/MediaMonitoring: This is experimental project how to use C# for Text Mining with pythonnet, sastrawi, nltk (github.com)
Sesuaikan Konfigurasi
- Install python ya versi 3.6 ke atas Download Python | Python.org
- Terus install pip Installation – pip documentation v22.0.4 (pypa.io)
- Install beberapa modul yang diperlukan : Sastrawi · PyPI nltk · PyPI
- Untuk nltk ada data yang perlu di download NLTK :: Installing NLTK
- Buka projectnya dengan Visual Studio lalu sesuaikan beberapa parameter antara lain : key API twitter dan letak dll python (pake python versi 3.6 ke atas aja ya)

- Lalu ya tinggal di Run, teken F5, tadaa…
Struktur Project
Project ini dibuat pakai .NET 6 Blazor Server, nah beberapa library yang kita butuhkan sudah di tambahkan dan beberap fungsi preprocessing diatas semua ada pada folder Helpers:

Silakan saja diterawang-terawang kodenya untuk dipahami.
Hasil
Hasil pencarian dari twitter dengan tweetvi

Hasil preprocessing: hapus tanda baca, stopword, stemming

Hasil Proses: menghitung kata

Visualisasi: word cloud

Ok, asik khan ? selamat berpetualang
Tetap berkarya, jangan mager
Salam Dev ;D
![]()