Salam Devs, selamat senin haha.. pasti bahagia kalau dengar hari senin. Kali ini kita akan membuat aplikasi untuk menampung arsip-arsip kita, tapi apa bedanya? bedanya kita dapat ngobrol sama arsip-arsip yang kita simpan? hah, ngayal kali sampeyan.. bener bisa kok. Ini di mungkinkan dengan menerapkan Retrieval Augmented Generative, yaitu kita cari konteks informasi terkait pada dokumen kita lalu kita jadiin konteks untuk melakukan prompting ke LLM (Large Language Model) seperti GPT, PaLM, Falcon, dsb.
Nah project open source ini bisa ditarik dari repo berikut Gravicode/DMSRAG: This is simple document repository app with RAG (Retrieval Augmented Generative) capability, built with SK and Blazor (github.com)
Adapun motivasi penulis simpel aja, semoga aplikasi ini bermanfaat dan barokah untuk yang membutuhkannya.


Nah cara kerjanya sesimpel ini:
- Kita parsing semua teks di dalam dokumen-dokumen kita menjadi potongan-potongan teks yang kecil, gunanya biar muat jadi konteks LLM yang terbatas karena masing-masing LLM punya limit window context-nya.
- Potongan kata-kata ini kita simpan sebagai vektor di vektor database macam Qdrant, pinecone, chroma, dsb. Tapi kali ini kita simpel di in-memory secara temporer saja.
- Saat kita melakukan pencarian kita lihat konteks yang paling dekat dengan keyword/prompt yang kita ketik, bisa dengan melihat cosine similarity atau metode lain. Kita ambil potongan” teks itu menjadi konteks untuk kita query ke LLM
- Kembalikan hasil-nya ke user
Simpel khan ? Nah implementasinya kita ga perlu koding semuanya dari scratch kita bisa memanfaatkan library Semantic Kernel dan Semantic Memory. Yaitu library untuk orkestrasi LLM dan juga library untuk melakukan RAG.

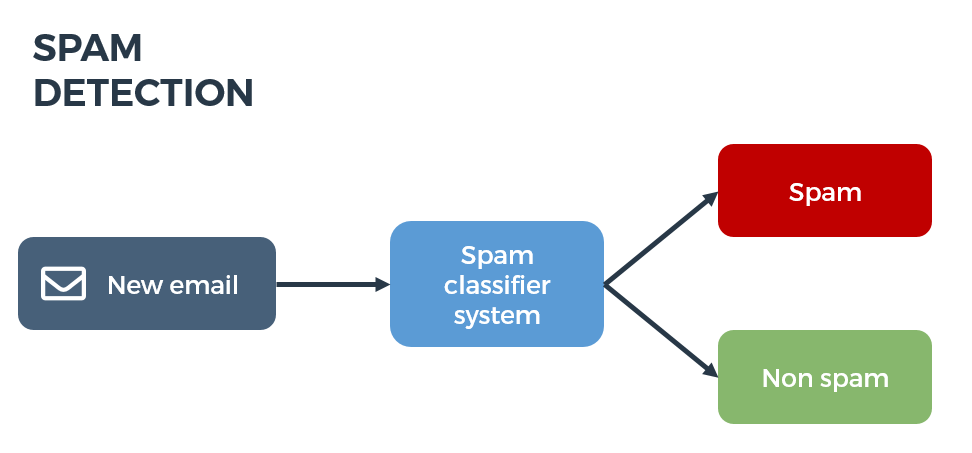
ini gambaran yang terjadi ketika kita melakukan indexing file

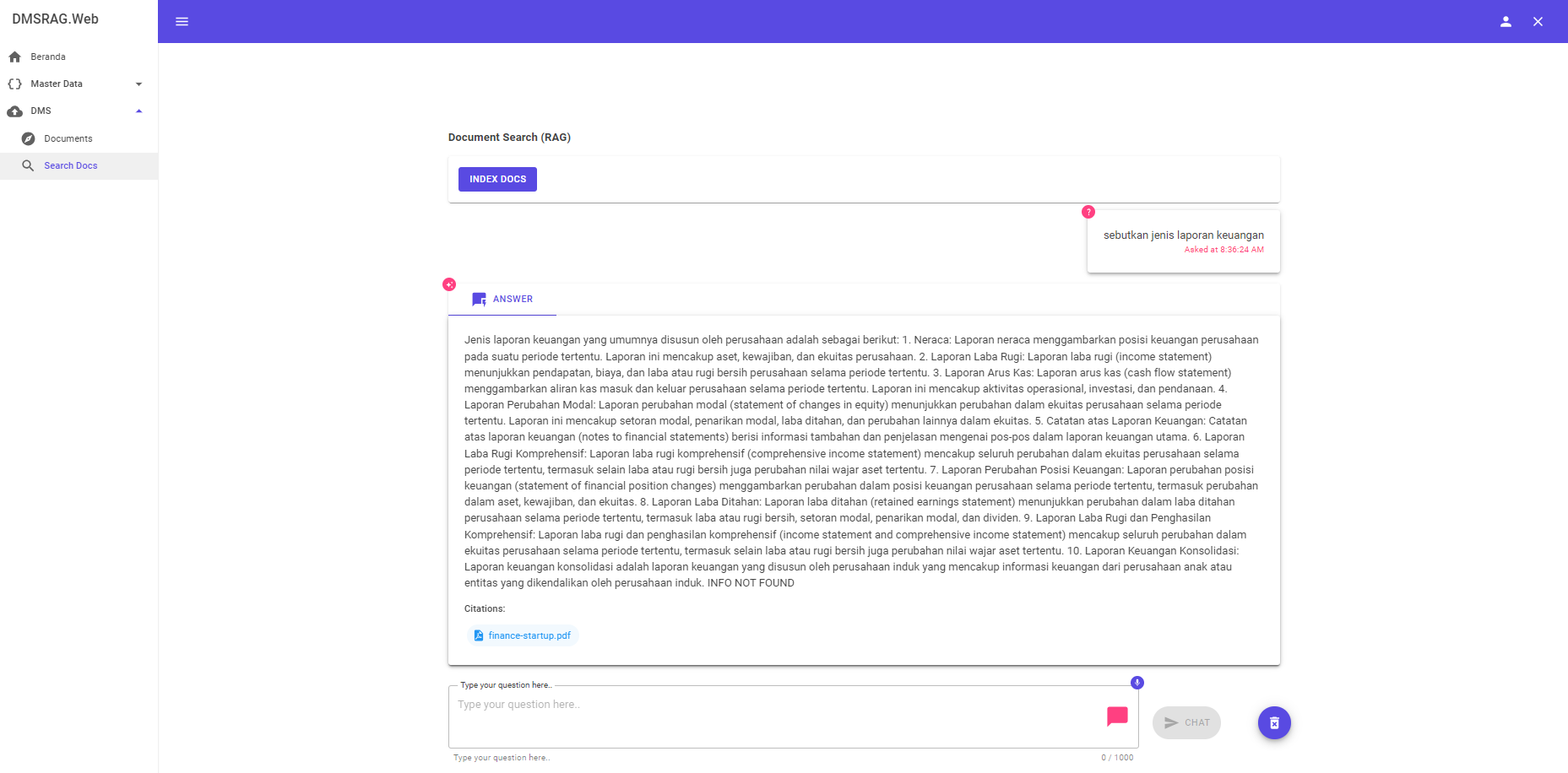
Ini gambaran ketika kita melakukan query ke dms
Saya cuma akan menghighlight sedikit potongan kode untuk melakukan indexing document dan RAG berdasarkan keyword.
- Lihat di file RAGChat.razor, pada file tersebut kita inisiasi dulu library Semantic Memory dengan cara seperti ini

- Lalu kita index document-document kita dengan cara seperti ini

- Kemudian kita query dokumen kita seperti ini

Beberapa info terkait project ini:
- Kita gunakan data storenya dengan redis, kenapa ? karena cepet aja, sama kita pake struktur data tree untuk mengorganisasi file kita yang lebih mudah disimpen dalam bentuk JSON, jadi NOSQL cocok lah
- Untuk vector database kita pake in-memory, dalam prakteknya nanti kode-nya tinggal ubah dikit supaya bisa pake Azure Cognitive Search atau Qdrant, atau lainnya (in the future).
- Ada fitur chat dengan dokumen spesifik, ini untuk membatasi konteks saja jika memang ingin mencari informasi tertentu pada dokumen spesifik (tidak keseluruh dokumen yang ada di DMS)
- Kalau delivery untuk skala besar silakan pisahkan fungsi indexing dan query RAG-nya ke service terpisah, dan manfaatkan semantic memory web client.
Ya penulis berharap project open source kaya gini bisa ada manfaatnya, dan dikembangkan lebih jauh bersama-sama penggiat open source di Indonesia. Biar ga mangkrak kaya skripsi”, thesis”, disertasi” di perpustakaan yang tidak dikembangkan jadi produk yang berdampak ;D
Salam Produktif ;D
![]()